A k-rotation (or a k-cyclic shift) of a sequence (a0a2...an-1) is a sequence (aP(1)aP(2)...aP(n-1)), where the index permutation is P(i) = (i + k) % n. The problem is to transform the given sequence into its k-rotation.
There are four well-known algorithms to do it:
- Dolphin algorithm:
Compute the number of cycles,
nc = gcd(k, n - k); for each cycle(aCi(0)aCi(1)aCi(2)...)withCi(j) = (i + jk) % n, i = 0, ..., nc - 1, make a cyclic shift of all the elements by one position to obtain(aCi(1)aCi(2)...aCi(0)). - Gries–Mills algorithm:.
If
k = n - k, swap the subsequences(a0...ak-1)and(ak...an-1); ifk < n - k, swap the subsequences(a0...ak-1)and(ak...a2k-1), then proceed recursively for the suffix subsequence(a0...ak-1a2k...an-1)withk' = k; ifk > n - k, swap the subsequences(a0...an-k-1)and(ak...an-1), then proceed recursively for the suffix subsequence(an-k...ak-1a0...an-k-1)withk' = 2k - n. - Using three reverses:
Reverse the subsequences
(a0...ak-1)and(ak...an-1), then reverse the whole sequence(ak-1...a0an-1...ak). - Direct copy using an additional memory buffer.
Below are the results for rotation of std::vector with N elements of type int. std::rotate is used as a baseline. Versions I and II of algorithms differ in some details, please refer to the source code.
The dolphin algorithm makes much fewer (~2-3 times) memory accesses. However, it is not cache-friendly and has poor performance in practice, as is vividly illustrated below.
Intel Core i7-4770 with GCC 8.3.0 (-O3 -m64 -march=native):
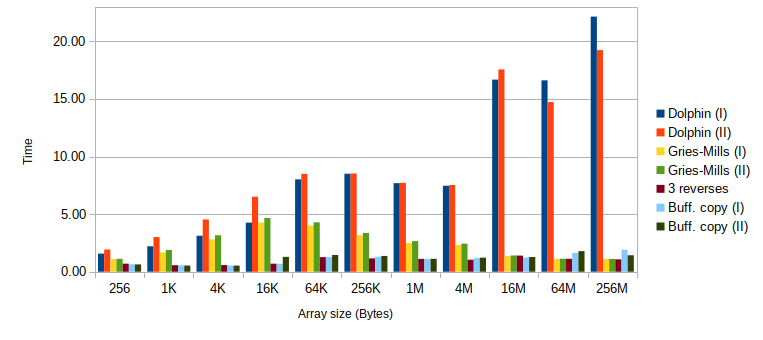
| N | Bytes | (1 I) | (1 II) | (2 I) | (2 II) | (3) | (4 I) | (4 II) |
|---|---|---|---|---|---|---|---|---|
| 64 | 256 | 1.57 | 1.93 | 1.09 | 1.12 | 0.70 | 0.64 | 0.63 |
| 256 | 1K | 2.21 | 3.01 | 1.68 | 1.89 | 0.57 | 0.56 | 0.54 |
| 1'024 | 4K | 3.12 | 4.54 | 2.81 | 3.16 | 0.58 | 0.54 | 0.53 |
| 4'096 | 16K | 4.26 | 6.51 | 4.28 | 4.66 | 0.70 | 0.69 | 1.29 |
| 16'384 | 64K | 8.02 | 8.49 | 4.01 | 4.29 | 1.27 | 1.27 | 1.45 |
| 65'536 | 256K | 8.50 | 8.53 | 3.17 | 3.37 | 1.16 | 1.30 | 1.37 |
| 262'144 | 1M | 7.69 | 7.72 | 2.51 | 2.66 | 1.12 | 1.12 | 1.12 |
| 1'048'576 | 4M | 7.46 | 7.52 | 2.33 | 2.44 | 1.04 | 1.20 | 1.22 |
| 4'194'304 | 16M | 16.68 | 17.56 | 1.36 | 1.41 | 1.40 | 1.23 | 1.28 |
| 16'777'216 | 64M | 16.62 | 14.73 | 1.11 | 1.13 | 1.12 | 1.63 | 1.79 |
| 67'108'864 | 256M | 22.14 | 19.23 | 1.11 | 1.11 | 1.07 | 1.92 | 1.43 |
Cache sizes on this CPU: L1 Data – 32K, L2 – 256K, L3 – 8M.
Intel Xeon E5-2650 v3 with GCC 7.3.0 (-O3 -m64 -march=native):
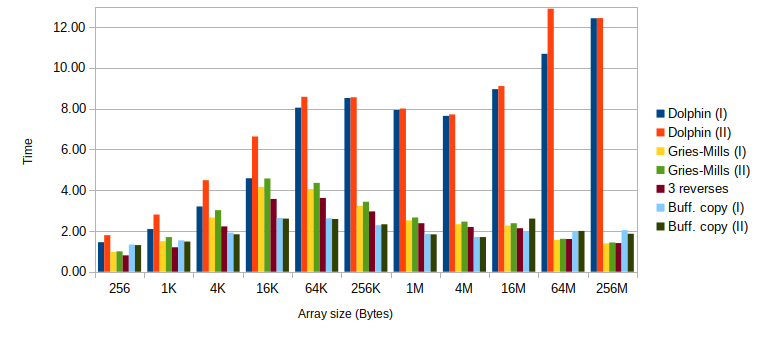
| N | Bytes | (1 I) | (1 II) | (2 I) | (2 II) | (3) | (4 I) | (4 II) |
|---|---|---|---|---|---|---|---|---|
| 64 | 256 | 1.45 | 1.80 | 0.97 | 1.00 | 0.80 | 1.33 | 1.31 |
| 256 | 1K | 2.10 | 2.81 | 1.50 | 1.70 | 1.20 | 1.54 | 1.48 |
| 1'024 | 4K | 3.20 | 4.49 | 2.66 | 3.02 | 2.22 | 1.92 | 1.84 |
| 4'096 | 16K | 4.59 | 6.64 | 4.16 | 4.57 | 3.57 | 2.64 | 2.60 |
| 16'384 | 64K | 8.05 | 8.58 | 4.05 | 4.36 | 3.62 | 2.62 | 2.59 |
| 65'536 | 256K | 8.52 | 8.56 | 3.23 | 3.43 | 2.96 | 2.28 | 2.33 |
| 262'144 | 1M | 7.93 | 8.01 | 2.52 | 2.66 | 2.38 | 1.85 | 1.83 |
| 1'048'576 | 4M | 7.65 | 7.72 | 2.33 | 2.46 | 2.20 | 1.70 | 1.70 |
| 4'194'304 | 16M | 8.96 | 9.11 | 2.26 | 2.38 | 2.13 | 1.96 | 2.61 |
| 16'777'216 | 64M | 10.69 | 12.90 | 1.56 | 1.61 | 1.61 | 1.98 | 2.00 |
| 67'108'864 | 256M | 12.43 | 12.44 | 1.39 | 1.43 | 1.41 | 2.04 | 1.86 |
Cache sizes on this CPU: L1 Data – 32K, L2 – 256K, L3 – 25M.
{kind=link}
{kind=link}